
Quelques découvertes informatiques en vrac
Les formulaires Google Drive
Le quiz sur les poissons d’avril m’a permis d’expérimenter la puissance et la facilité d’utilisation des formulaires Google Drive . C’est simplement génial :
- dans Google Drive, on crée un document de type formulaire
- on se retrouve dans un éditeur permettant de composer le formulaire. On peut définir le type de chaque champ : texte, choix multiple, cases à cocher, échelle d’évaluation, tout y est. On peut ajouter des règles de validation et des actions à effectuer en fonction des réponses

Editeur de Formulaire Google Drive - En cliquant le bouton « afficher le formulaire en ligne » on peut voir à quoi ça ressemble pour les utilisateurs et même tester le système, car la collecte des réponses est immédiate : rien à faire de particulier !
- Lorsque le formulaire est prêt, il suffit d’envoyer le lien disponible par « Envoyer le formulaire » à des personnes choisies, ou d’intégrer la page sur un site web dans un <iframe>. Plusieurs blogs du C@fé des sciences l’ont même fait simultanément sans aucun problème car le formulaire n’existe en réalité (virtuelle…) que chez Google.
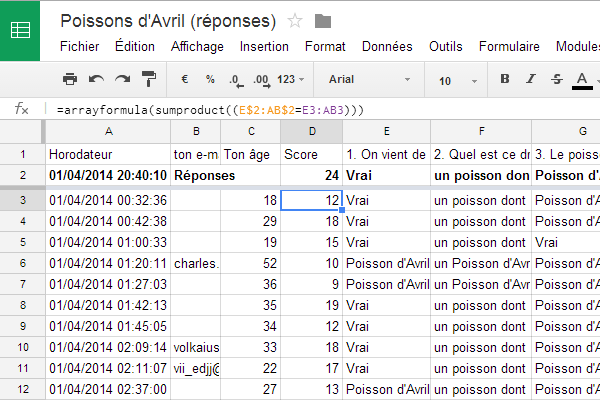
- Les réponses sont automatiquement collectées dans un document « tableur » sur Google Drive : une ligne est créée pour chaque formulaire rempli, chaque colonne correspondant à un champ. Notez la colonne « horodateur » remplie automatiquement, bien utile.
Table des résultats Ce que j’ai trouvé assez impressionnant est que l’on peut modifier le tableau sans perturber les votes suivants. Apparemment chaque champ du formulaire est attaché à une colonne par un lien invisible, mais solide : même si on ajoute ou déplace des colonnes, les réponses suivantes restent cohérentes avec les réponses précédentes. Pour le quiz, j’ai ajouté la ligne 2 avec les bonnes réponses ainsi que la colonne D Score. Notez au passage la géniale formule qui compte le nombre de réponses correctes avec arrayformula et sumproduct. Elle n’est pas de moi, et il parait qu’elle est possible aussi en Excel…
-
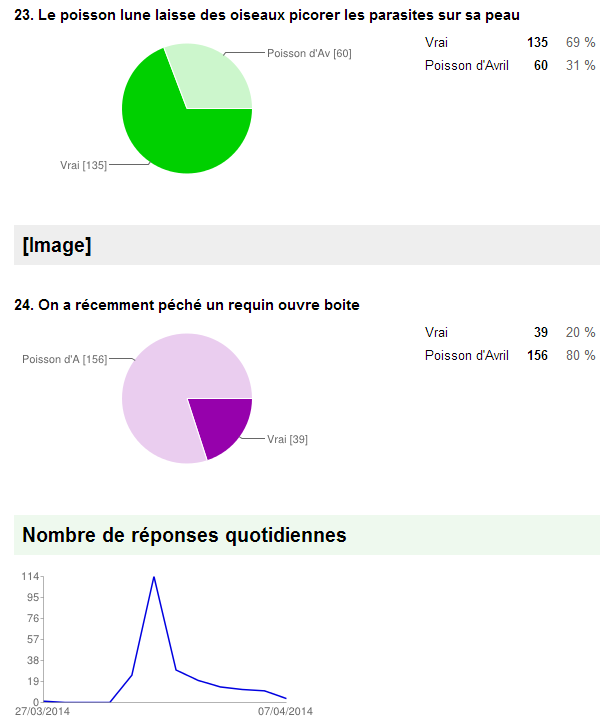
résumé des réponses Une petite dernière pour la route : dans le menu « Formulaire » on peut « afficher le résumé des réponses » qui présente les résultats sous une forme graphique qui peut être bien utile.

Les formulaires Google Drive permettent de réaliser facilement des sondages, quiz et concours divers avec toute la puissance et la sécurité (…) de l’infrastructure Google. Ca fait déjà des émules dans le C@fé …
Curation V.3.0
Rien à faire, il n’y a toujours pas mieux pour suivre les sites intéressants que les flux RSS. J’ai longtemps utilisé Google Reader avec lequel j’ai commencé à faire de la curation de contenu. En effet, en cochant simplement les articles que je trouvais intéressants, Google Reader les agrégeait dans un flux RSS « de sortie » que je pouvais publier sur ma page Facebook.
Puis Google a annoncé la fermeture de Reader (toujours incompréhensible pour moi) et j’ai utilisé Scoop.it. C’était une bonne idée : Scoop.it permet d’agréger non seulement des flux RSS, mais aussi des tweets, le contenu de pages Facebook et de recherches Google. On peut créer ainsi plusieurs « topics » thématiques, et de jolis widgets comme celui ci-contre à droite. Mais le point fort de Scoop.it, c’est ses possibilités de partage : chaque contenu « scoopé » peut être partagé automatiquement sur Twitter, Facebook, Gogle+ et Tumblr, entre autres.
Scoop.it, c’est vraiment bien, mais … il y a un problème rédhibitoire : les liens du contenu partagé sont modifiés pour conduire les visiteurs sur la page Scoop.it du topic, et pas directement vers l’article original. Ceci a trois conséquences que je trouve gênantes:
- La première n’est pas trop grave : les lecteurs doivent cliquer deux fois pour arriver à l’article qui les intéresse, une fois sur la page où ils voient le contenu partagé, puis une seconde fois sur la page Scoop.it.
- La seconde fausse les analyses de trafic, qui semble provenir de Scoop.it plutôt que du site de partage. Ainsi par exemple mon site a accueilli plus de 2000 visiteurs passés par Scoop.it en un an sans qu’il me soit possible de déterminer où ces 2000 personnes ont initialement découvert l’article qui les intéressait.
- La troisième touche le droit d’auteur : les outils de partage qui changent les liens diffusent le contenu d’autrui en coupant le lien vers la source, qui est parfois le seul élément identifiant l’auteur. Je me suis soudain aperçu que mon Tumblr « rebloguait » automatiquement les articles que je trouvais intéressants, parfois en me les attribuant implicitement puisqu’il n’y avait plus de mention du site original.
Je me suis donc mis en chasse de nouveaux outils de curation, et après quelques essais j’ai choisi le « trio de la curation V.3 » :
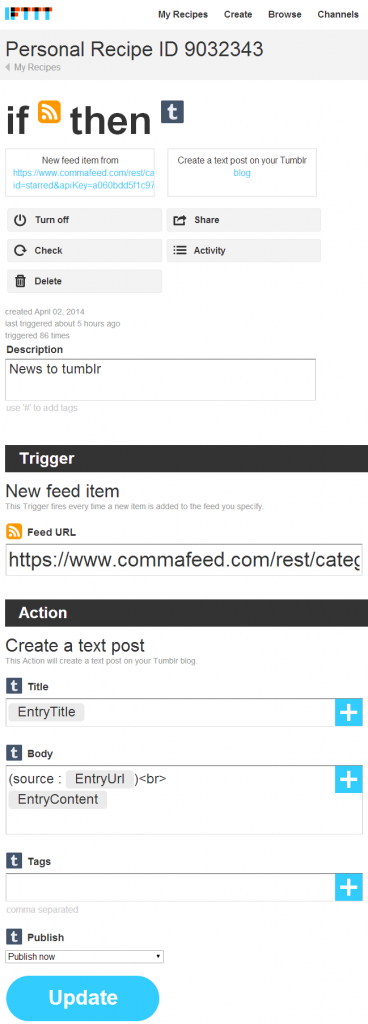
- CommaFeed comme agrégateur de flux. Il offre grosso-modo les fonctionnalités de Google Reader, une extension Chrome, plus une application Android (en fait un plugin d’un agrégateur plus général). Chaque jours je parcours une centaine d’articles en sautant d’un à l’autre en pressant la touche [j], et si je le trouve intéressant je le lis et je presse [s] comme « star ». Ca le marque comme favori et l’ajoute à mon flux RSS de sortie.
- Je pourrais utiliser directement CommaFeed pour partager le contenu sur Facebook, Twitter, Google+ et autres (mais pas Tumblr). Mais surtout, il me faudrait le faire manuellement : 6 ou 8 clicks de plus, c’est trop. Alors j’ai utilisé IFTTT.com, un service qui permet d’automatiser des tâches internet en créant des « recettes » de la forme If This Then That . J’ai ainsi créé des « recettes » qui partagent automatiquement le contenu de mon flux de sortie vers mes pages Facebook, Google+, App.net et Tumblr. Automatiquement. Rien d’autre à faire 🙂 (Pour Twitter j’hésite encore…)
- Et j’utilise toujours Scoop.it pour atteindre les utilisateurs de cette plateforme et profiter des beaux widgets, mais je n’utilise plus les outils de partage. En attendant qu’IFTTT permette de « scooper » automatiquement, j’utilise le flux de sortie comme unique source dans Scoop.it et je « scoope » à la main tout ce que j’ai préalablement sélectionné dans CommaFeed.
Tout ça ne me demande en définitive pas plus d’efforts que de tourner les pages d’un journal en papier, et je peux me concentrer sur la lecture tout en gardant une trace dont vous pouvez profiter où vous le souhaitez.
NetworkX
NetworkX est une librairie Python permettant de représenter et traiter des problèmes de graphes. Je l’utilise professionnellement assez intensivement ces temps-ci pour un problème de postiers chinois, mais l’autre jour il m’a permis de résoudre le problème 107 du Project Euler en quelques lignes seulement. En fait la plupart servent à lire le fichier des données, puis la partie intéressante tient en une seule ligne :
print G.size(weight='weight') - minimum_spanning_tree(G, weight='weight').size(weight='weight')
Fort non ? Hélas il me semble que peu de problèmes du Project Euler concernent les graphes, donc je ne vais pas pouvoir améliorer mon score rapidement …
2048
 Cet article serait paru il y a trois jours si je n’étais pas tombé sur 2048, le jeu addictif du moment. C’est un jeu tellement simple qu’il aurait du être inventé avant Pac-Man. Et on voit tout de suite comment faire : placer les puissances de 2 les unes à côté des autres pour former une chaîne croissante et propager ainsi les sommes pour arriver à former enfin, après 1024 coups au minimum, la tant convoitée pièce 2048. Il m’a fallu 3 jours. Enfin 3 soirs. 3 nuits…
Cet article serait paru il y a trois jours si je n’étais pas tombé sur 2048, le jeu addictif du moment. C’est un jeu tellement simple qu’il aurait du être inventé avant Pac-Man. Et on voit tout de suite comment faire : placer les puissances de 2 les unes à côté des autres pour former une chaîne croissante et propager ainsi les sommes pour arriver à former enfin, après 1024 coups au minimum, la tant convoitée pièce 2048. Il m’a fallu 3 jours. Enfin 3 soirs. 3 nuits…
A un certain moment j’en ai eu marre et voulu utiliser la bonne vieille méthode pour résoudre les problèmes compliqués : programmer. Mais Matt Overlan a été plus rapide et efficace : son solveur fonctionne très bien et est très instructif. Je crois que c’est la première fois de ma vie qu’un ordinateur m’apprend à résoudre un casse-tête plutôt que l’inverse. Peu après avoir observé le solveur parvenir au 2048, j’ai appris à dominer ma tentation d’additionner coûte que coûte les nombres les plus élevés et à conserver des lignes ou des colonnes de 4 cases « bloquées », et j’ai gagné.
Après certains passent au 4096 voire au 9007199254740992, mais je crois que je vais plutôt attaquer la version « échelle du vivant » de Valentine. Un peu déroutant de prime abord, mais j’aime beaucoup l’idée un peu holiste qu’il y a là derrière… Bravo !




7 commentaires sur “Bits en vrac”
Je me penche sur le « Maximum clique problem (MCP) » avec NetworkX; n’ayant que les bases de licence sur la théorie de graphe, j’avoue tâtonner un peu… Quelqu’un a t’il des retours positif sur la fonction max_clique (pour des graphes de plus de 1000 sommets…)?
Je ne l’ai pas utilisée mais d’après le manuel la complexité de l’algo est O(|V|/(log|V|)2) donc ne devrait pas poser de problème pour 1000 sommets, ni même pour beaucoup plus.
C’est étonnant parce que le problème de la clique maximum est NP-difficile comme souligné dans le code source https://github.com/networkx/networkx/blob/master/networkx/algorithms/clique.py …
Mais tiens, max_clique n’est pas défini dans ce module mais dans celui ci : https://github.com/networkx/networkx/blob/master/networkx/algorithms/approximation/clique.py . C’est un algorithme approximatif : il est rapide, mais tu n’es pas sur d’obtenir le maximum absolu. Rapide ou sur, il faut choisir …
Si tu as des questions pointues sur NetworkX, je te suggère de les poser sur StackOverflow qui est très actif et réactif. Voir http://stackoverflow.com/search?q=networkx+clique sur ce sujet par exemple.
Bonjour !
Merci pour cet article qui me conforte dans l’idée que je ne suis pas le seul à couper les bits en quatre. Et, oui, pourquoi Google Reader est-il décédé ?
Côté curation et pour ceux que ça intéresse, vous trouverez dans cet article les outils que j’utilise…
http://www.blog.francis-leguen.com/veille-thematique-et-curation-automatique-les-outils-indispensables/
2048 est une vraie drogue. C’est de l’incitation à la toxicomanie ce que tu fais là!!
J’ai pas regardé ce que fait le solveur, mais je pense trouver un algo pour le résoudre avec une très bonne probabilité. Je verrai si j’ai le courage de l’implémenter, et je comparerai avec celui en lien.
En fait tu peut très facilement forker le projet https://github.com/ov3y/2048-AI et implanter ton algo en modifiant https://github.com/ov3y/2048-AI/blob/master/js/ai.js …
Pour les graphs, sciyp fait le boulot avec scipy (scipy.sparse.csgraph) un très bon package. A utiliser avec ipython et son notebook.
Pour les problèmes d’optimisation discrète il y en ce moment sur coursera un très bon cours sur coursera intituler « discrete optimisation » https://www.coursera.org/course/optimization
Dommage c’est la fin du cours mais essaye de choper le matériel ça vaut le coup.
merci pour les tuyaux ! En effet avec http://docs.scipy.org/doc/scipy/reference/sparse.csgraph.html ça doit être encore plus simple parce que la matrice d’adjacence contient directement les poids, alors que NetworkX considère les poids comme des attributs attachés aux arcs.
Le cours Coursera a l’air très bien, mais je crois que j’en suis déjà un peu plus loin … Une partie visible est ici https://github.com/goulu/Goulib/blob/master/Goulib/graph.py et pour le reste faudra attendre le brevet 😉