 Si vous ne connaissez pas Shazam, demandez à un propriétaire d’iPhone (eux) ou de Google Phone sous Androïd (nous) de vous montrer cette application incroyable. Si personne dans votre entourage ne vit au 21ème siècle, vous pouvez toujours regarder cette démonstration en video.
Si vous ne connaissez pas Shazam, demandez à un propriétaire d’iPhone (eux) ou de Google Phone sous Androïd (nous) de vous montrer cette application incroyable. Si personne dans votre entourage ne vit au 21ème siècle, vous pouvez toujours regarder cette démonstration en video.
Vous ne rêvez pas : Shazam est capable d’identifier en quelques secondes la musique que vous êtes en train d’écouter à la radio, dans un bar bruyant, ou le générique d’une émission TV ou que sais-je. On dirige le micro du téléphone vers un haut-parleur, on clique un seul bouton et Shazam! le titre du morceau apparait, avec les liens qu’il faut pour l’acheter, évidemment. Business is business.
Ce qui nous intéresse ici, c’est de savoir comment diable Shazam fait pour reconnaitre quasi-instantanément 10 secondes de son parmi 8 millions de morceaux de musique de 3 minutes chacun, soit un total de 1.44 milliards de secondes, ou 45 ans de musique, et ceci même lorsque la musique est diffusée par une mauvaise sono et captée par un mauvais micro dans un environnement bruité. Ca ne vous épate peut être pas si vous n’êtes pas dans la technique, mais moi je suis resté coi d’une hébétude aussi stupéfaite qu’interloquée. Sur le cul, quoi.
Pour comprendre, j’ai un peu fouillé et trouvé que la technologie appartient à Landmark Digital qui a notamment acquis la propriété intellectuelle de dénommés Avery Wang et David Culbert. Leur brevet de 2003 [1] est un modèle du genre : il décrit le système en termes suffisamment généraux pour comprendre le principe, mais en évitant soigneusement de donner des informations précises sur comment ça marche vraiment. Mais voici tout de même ce que j’en ai compris.
Shazam compare des « empreintes » calculées à des instants remarquables du morceau, par exemple lorsque des notes apparaissent nettement dans le diagramme temps/fréquence du morceau. Pour des raisons expliquées plus bas il faut comparer environ une centaine d’empreintes, et comme Shazam demande d’enregistrer une dizaine de secondes de musique, j’en déduis qu’ils prennent environ 10 empreintes par seconde, donc que chaque morceau est stocké chez eux sous la forme de 1800 empreintes environ.
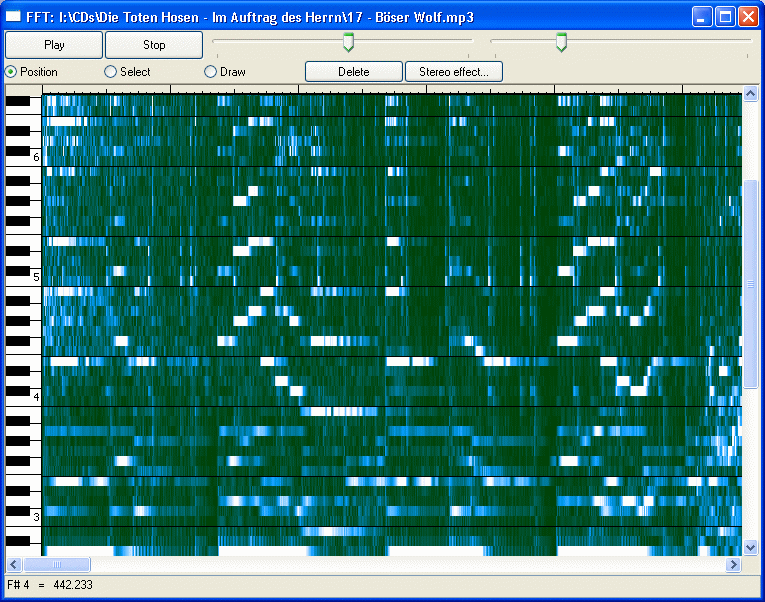
Le brevet est extrêmement vague sur le problème clé du calcul des empreintes. Il mentionne une liste de caractéristiques du son qui pourraient être utilisées, et indique qu’un choix judicieux permet de s’affranchir de diverses perturbations du son, en particulier de décalages fréquentiels, mais surtout que l’empreinte peut être ramenée à un nombre de 32 bits seulement. Avec ce qui précède, il en résulte que les empreintes d’un morceau complet ne nécessitent que 7K de mémoire, et que toute la base de données de Shazam tient sur 54 Gigabytes seulement, ce qui veut dire qu’elle peut tenir dans la mémoire RAM d’une vingtaine de PC actuels.
Reste à retrouver dans cette masse d’empreintes la centaine d’empreintes obtenues à partir de la musique transmise depuis votre téléphone. Et là, la méthode est génialement simple : Pour chaque empreinte, Shazam regarde à quels morceaux elle pourrait appartenir en utilisant simplement l’empreinte comme une clé dans la base de données. En effet, comme 32 bits permettent de coder plus de 4 milliards de possibilités alors que la base ne contient « que » 14 milliards d’empreintes, une empreinte donnée se retrouve en moyenne dans 3 morceaux seulement. Puisque les empreintes tirées de l’échantillon sont bruitées, il faut comparer une centaine d’empreinte qui vont chacune correspondre à 3 morceaux, donc on se retrouvera avec 300 morceaux potentiellement candidats.
C’est là que le brevet de Shazam frappe fort : si 2 empreintes seulement correspondent à un même morceau, on considère que c’est celui-là ! En effet, il n’y a qu’environ un risque sur 25’000 que l’un des 300 morceaux suspecté à cause d’une empreinte bruitée corresponde à l’un des 3 morceaux identifié par une empreinte correcte.
La technologie de Shazam/Landmark permet aussi d’autres applications, comme reconnaître la musique utilisée dans les bandes son des vidéos sur YouTube et la virer si elle est soumise à copyright, ou peut-être aussi identifier des mp3 échangés sur des réseaux p2p, des trucs comme ça …
Car pour la reconnaissance de la musique, il y a désormais encore plus fort que Shazam : Midomi. Avec Midomi, il suffit de chantonner, siffloter ou hmmm-hmmm-er un air pour qu’il en retrouve le titre et l’auteur. Mais ça m’épate moins parce qu’avec moi, ça ne marche pas. Ni « Yellow Submarine », ni « Frère Jacques », ni même l’air de la reine de la nuit façon Foster Jenkins, rien.
Référence
- WANG, Avery Li-Chun and CULBERT, Daniel, « Robust and invariant audio pattern matching », 2003, patent WO03091990A1
- Avery Wang, « An Industrial-Strength Audio Search Algorithm », 2003, ISMIR 2003, 4th International Conference on Music Information Retrieval, Baltimore, Maryland, USA [article pdf] [slides pdf]
- [altmetric doi= »10.1145/1145287.1145312″ float= »right »] Avery Wang « The Shazam music recognition service », 2006 , Communications of the ACM – Music information retrieval Volume 49 Issue 8, Pages 44-48 DOI>10.1145/1145287.1145312




{kind=link}
{kind=link}
90 commentaires sur “Comment marche Shazam”
Bonjour,
Savez-vous si TrackID de chez sonyericsson (powered by gracenote) a quelquechose à voir avec shazam ? Car mon modeste w910i me rend ce précieux service depuis bientôt 3 ans. À qui l’antériorité ?
Merci pour cet article fort intéressant
j’ai trouvé la page des brevets de Gracenote ici et il y en a une collection impressionnante, en effet. Je n’ai pas le temps de lire tous les brevets, mais les résumés donnés sur la page sont intéressants. Il y a des points communs avec Shazam, comme les empreintes prises à des moments remarquables, mais Gracenote a l’air d’utiliser le rythme alors que Shazam n’y fait pas référence. Les deux prennent des caractéristiques temps/fréquence pour générer les empreintes. Mais la différence est que Gracenote calcule une « distance », ou une similarité entre les empreintes alors que Shazam considère que 2% des empreintes doivent être rigoureusement identiques.
Un autre point commun de ces brevets est qu’il n’y a pas besoin de traiter le son au niveau du téléphone. Il suffit d’envoyer 10 secondes en continu au serveur, ce qui fait que ça peut marcher avec n’importe quel téléphone, effectivement. On peut imaginer qu’à l’avenir les empreintes soient calculées dans le téléphone, mais à quoi bon…
Le brevet de Shazam date de 2003, ceux de Gracenote sur le sujet remontent à 2006, longtemps après ceux des années 2000 sur l’identification des morceaux de musique sans perturbation. A première vue je dirais donc plutôt que c’est Shazam qui a sérieusement perturbé les plans de Gracenote…
Un brevet ne protège pas une idée, il protège une manière de réaliser cette idée. En l’occurence, l’idée d’un système pouvant reconnaitre un morceau de musique est probablement très ancienne, mais Shazam, Gracenote et d’autres ont trouvé divers moyens plus ou moins élégants de la réaliser. Il faudrait être juriste pour déterminer si ces brevets se recouvrent, et si ça vaut la peine d’aller en justice.
oui je suis d’accord, l’idée de midomi est bluffante, mais le résultat décevant: moi quand je sifflote « I’m singing in the rain », Midomi me propose bien le bon titre, mais dans la version sifflotée par un autre quidam qui a le même mauvais sens musical que moi! Mais ça va sûrement s’améliorer très vite…
En attendant, l’effet indirect c’est que les radios se mettent enfin à indiquer par le signal RDS le titre des chansons qu’elles passent, je suppose pour éviter de se faire court-circuiter par Shazam et itunes. Quelle réactivité! Sauf que ça fait au moins 20 ans que le RDS leur permettait de faire ça, mais qu’elles avaient la flemme. Merci Shazam! Cela dit, j’exagère un peu quand je parle DES radios. C’est vrai qu’aux US elles s’y sont mises, mais en France je n’ai trouvé que RTL2 qui utilise enfin le RDS pour rendre ce service.
Bonjour, en ce qui concerne le RDS, nous avons effectivement un retard phénoménal (NRJ et Radio Classique se sont lancées dans la course). En Italie cette pratique s’est généralisée avec des messages de toutes sortes diffusés en fonction de la programmation.
le RDS c’est sympa, mais quel avantage les radios ont-elles de le diffuser ? Sur Shazam il y a un lien pour acheter le morceau, qui n’existe pas (encore) sur mon poste de radio. A part si les majors font des rabais de droits d’auteur aux radios qui utilisent le RDS, je ne vois pas pourquoi elles se fatigueraient …
L’avantage d’utiliser le RDS pour les radios? Par exemple endiguer la perte d’audience colossale dont elles n’ont pas vu le quart du début: avec Deezer, les radios sur le net, YouTube + la généralisation de l’accès à internet en mobilité (iphone, smartphones etc) quel est l’intérêt d’écouter la radio, si on ne peut même pas savoir le titre de la chanson qui passe? Et à terme pourquoi pas, envoyer un code promo pour télécharger le titre en question à prix intéressant…
Bonjour,
justement, je remarque que les grosses radios ne donnent pas le titre en RDS : cela force l’auditeur à écouter la fin de la chanson et parfois la suivante pour en connaitre le titre. Le titre en RDS est donc contraire à la fidélisation. A l’inverse, le nom de la radio en RDS permet la fidélisation.
D’autre part, shazam peut leur faire concurrence mais typiquement, au volant, un coup d’œil à l’écran de mon autoradio ne met pas en danger comme le ferait l’action de déclencher shazam, attendre puis lire le titre quand ça vibre.
PS : merci pour l’explication claire que je n’avais pas pris le temps de chercher.
Bonjour,
Savez-vous si TrackID de chez sonyericsson (powered by gracenote) a quelquechose à voir avec shazam ? Car mon modeste w910i me rend ce précieux service depuis bientôt 3 ans. À qui l’antériorité ?
Merci pour cet article fort intéressant
oui je suis d’accord, l’idée de midomi est bluffante, mais le résultat décevant: moi quand je sifflote « I’m singing in the rain », Midomi me propose bien le bon titre, mais dans la version sifflotée par un autre quidam qui a le même mauvais sens musical que moi! Mais ça va sûrement s’améliorer très vite…
En attendant, l’effet indirect c’est que les radios se mettent enfin à indiquer par le signal RDS le titre des chansons qu’elles passent, je suppose pour éviter de se faire court-circuiter par Shazam et itunes. Quelle réactivité! Sauf que ça fait au moins 20 ans que le RDS leur permettait de faire ça, mais qu’elles avaient la flemme. Merci Shazam! Cela dit, j’exagère un peu quand je parle DES radios. C’est vrai qu’aux US elles s’y sont mises, mais en France je n’ai trouvé que RTL2 qui utilise enfin le RDS pour rendre ce service.
« peut-être aussi identifier des mp3 échangés sur des réseaux p2p »
mais ce qui marche avec du son marcherait-t-il avec des données compressées?
bon, ok il faut décompresser le mp3 avant la comparaison. Mais le système « Shazam » permet de reconnaitre un morceau encodé en 128 bits/s, en 192 ou en 256, ou avec différents encodeurs mp3, bref, on peut reconnaitre le morceau de musique plutôt que le fichier…
alors ça ne me paraît pas une bonne solution pour surveiller les réseaux P2P, d’autant que les fichiers voyagent par petits bouts…
enfin, s’ils ont le brevet pour ça, tant mieux pour eux ;-p
Hello,
Ce qui serait intéressant, c’est de faire reconnaitre un morceau passé sur un vinyle ralentit ou accéléré. Ainsi le rythme du tempo et les fréquences de la voix de tête (probablement la seule identifiée) sont décalées.Si les empreintes sont calculées avec une « auto-correction », ça passe. Et que se passe-t-il pour un morceau avec 2 parties très différentes, comme Suspicious Mind de Elvis, si les 10 secondes sont à demi sur le ralentendo? C’est pire que du bruitage…
ce sujet est explicitement couvert dans le brevet. L’empreinte de Shazam est calculée pour être indépendante du « playback rate » donc de « frequency shift ». Pour « Suspicious Mind », il faut essayer… Mais avec Shazam, les empreintes ne sont pas prises à intervalles réguliers, mais à des « instants remarquables ». Si le bruit est tel qu’un « instant remarquable » sur le morceau de référence n’est pas détecté sur l’extrait enregistré, tu as une empreinte de moins, mais ce n’est pas grave car la comparaison ne se fait pas sur les successions d’empreintes. Il suffit de 2 empreintes « bonnes » pour l’identification!
« peut-être aussi identifier des mp3 échangés sur des réseaux p2p »
mais ce qui marche avec du son marcherait-t-il avec des données compressées?
Hello,
Ce qui serait intéressant, c’est de faire reconnaitre un morceau passé sur un vinyle ralentit ou accéléré. Ainsi le rythme du tempo et les fréquences de la voix de tête (probablement la seule identifiée) sont décalées.Si les empreintes sont calculées avec une « auto-correction », ça passe. Et que se passe-t-il pour un morceau avec 2 parties très différentes, comme Suspicious Mind de Elvis, si les 10 secondes sont à demi sur le ralentendo? C’est pire que du bruitage…
Je n’y crois pas à cette version qui est partout sur le net. Vous vous rendez compte du temps qu’il faut pour comparer un morceau enregistré à 8 millions de titres? improbable. il y a une technique de tri, par exemple par tempo, c’est indéniable? incroyable de ne pas trouver l’info.
Si tu n’y crois pas, c’est que tu n’as pas bien lu l’article, ou que tu ne l’as pas compris, donc que je l’ai mal écrit. Et c’est vrai que j’aurais pu être plus clair pour les lecteurs qui ne maitrisent pas l’algorithmique…
Ce que j’ai omis de dire parce que ça semblait évident à mes yeux d’informaticien, c’est qu’il n’y a pas besoin de faire des comparaisons pour savoir à quel morceau correspond une empreinte! Dans le cas le plus simple, il suffit de regarder dans une table : une fois une empreinte x calculée, il suffit de chercher pointer sur le x-ième enregistrement d’une table, qui contient le numéro du morceau présentant cette empreinte, et voilà! On répète cette recherche quasi instantanée 100 fois, et si deux recherche donnent le même résultat, c’est gagné.
En pratique, c’est un peu plus compliqué parce que plusieurs morceaux (3 en moyenne) peuvent correspondre à une même empreinte, mais l’invention de Shazam est bien là : il n’y a PAS besoin de faire de nombreuses comparaisons en calculant une ressemblance avec les 8 millions de morceaux.
Et ça je crois être le seul du web à l’avoir expliqué en français, parce que j’ai lu le brevet, moi 😉
Entre parenthèses, le « tempo » n’est pas un bon choix de paramètre : quand il y en a un il varie dans un morceau, il est difficile de le mesurer à la microseconde près (nécessaire pour distinguer des millions de morceaux) et les erreurs dans la vitesse de rotation des CD ou lors de conversions de format sont élevées par rapport à cette précision. Mais trouver de « bonnes » infos résistantes aux perturbations et au bruit, c’est effectivement le vrai challenge et le brevet de Shazam est assez vague sur ce sujet…
Je n’y crois pas à cette version qui est partout sur le net. Vous vous rendez compte du temps qu’il faut pour comparer un morceau enregistré à 8 millions de titres? improbable. il y a une technique de tri, par exemple par tempo, c’est indéniable? incroyable de ne pas trouver l’info.
Bonjour,
effectivement je n’avais lu qu’en travers l’article et assimilé à la majorité des autres que l’on trouve. Avec les transformées de Fourier à des instants remarquables ça colle pas mal. Je reste étonné de cette technique et du faible temps qu’elle prend.
Il est vrai que le filtrage du bruit par Shazam doit être assez remarquable, j’ai fait des essais dans des circonstances assez terribles.. L’appli me mettait déjà sur le cul, on m’avait expliqué le fonctionnement et je n’y croyait pas du tout..
Merci pour les explications en tout cas.
Bonjour,
effectivement je n’avais lu qu’en travers l’article et assimilé à la majorité des autres que l’on trouve. Avec les transformées de Fourier à des instants remarquables ça colle pas mal. Je reste étonné de cette technique et du faible temps qu’elle prend.
Il est vrai que le filtrage du bruit par Shazam doit être assez remarquable, j’ai fait des essais dans des circonstances assez terribles.. L’appli me mettait déjà sur le cul, on m’avait expliqué le fonctionnement et je n’y croyait pas du tout..
Merci pour les explications en tout cas.
Bonjour!
Tout d’abord merci pour cet article qui dévoile une petite partie de l’iceberg de Shazam! Tu as l’air bien informé au sujet de cette application!
En fait j’écris ce commentaire pour prendre contact avec toi car tu as peut-être des informations qui peuvent m’être utilies!
Je m’explique, je suis étudiant en 3eme informatique et système à l’ISIMs et je dois trouver un sujet de TFE.
J’ai un sujet assez ambitieux que j’aimerais réaliser, il s’agit d’un site internet fonctionnant comme shazam. Je sais pas si tu connais watzatsong mais ce serait dans le genre, les gens viendraient déposer leurs extraits à identifier et recevraient la réponse dans les 10 secondes, comme Shzam! J’ai bien compris le principe avec les empreintes et le système de comparaison mais j’aimerais avoir, si possible des informations plus précises si tu en possède!
Merci d’avance!
Je ne connais pas particulièrement Shazam, mais comme je le dis dans l’article j’ai été « scié » en le découvrant, et comme chercheur, j’ai cherché comment ça marchait…
A mon avis c’est beaucoup plus un problème de traitement du signal qu’un problème réellement informatique. Il s’agit de calculer les fameuses empreintes de manière à être:
1) au minimum, insensible au décalage temporel de l’échantillon par rapport à la référence. Autrement dit il faut pouvoir déterminer des « instants remarquables » sur la musique
2) si possible, que les empreintes soient insensibles à une limitation de la bande passante telle que celle qu’on subit en enregistrant avec un téléphone portable
3) et au maximum insensible au bruit ambiant… Quand on écoute les échantillons sur Watzatsong, ça fait peur…
Bref je ne me rends pas compte du niveau exigé par ton TFE de l’ISIMs (chez moi c’est la Suisse), mais je dirais que si tu arrives à faire un système d’empreinte qui marche sur des échantillons de bonne qualité (mp3), en ne satisfaisant que le point 1 ci-dessus, ce serait déjà pas mal du tout, en gardant les points 2 et 3 à l’esprit.
En y réfléchissant, je me dis que ça serait intéressant de trouver les morceaux qui ressemblent à l’échantillon, notamment au niveau rythmique, par exemple pour faire des fondus enchaînés impeccables.
Merci pour ta eéponse!!
Je te tiendrai au courant de l’évolution!
C’est vrai que ce serait top pour les mix parfaits lol je fais de la sono aussi ^^
A bientot j’espère!!
Bonjour!
Tout d’abord merci pour cet article qui dévoile une petite partie de l’iceberg de Shazam! Tu as l’air bien informé au sujet de cette application!
En fait j’écris ce commentaire pour prendre contact avec toi car tu as peut-être des informations qui peuvent m’être utilies!
Je m’explique, je suis étudiant en 3eme informatique et système à l’ISIMs et je dois trouver un sujet de TFE.
J’ai un sujet assez ambitieux que j’aimerais réaliser, il s’agit d’un site internet fonctionnant comme shazam. Je sais pas si tu connais watzatsong mais ce serait dans le genre, les gens viendraient déposer leurs extraits à identifier et recevraient la réponse dans les 10 secondes, comme Shzam! J’ai bien compris le principe avec les empreintes et le système de comparaison mais j’aimerais avoir, si possible des informations plus précises si tu en possède!
Merci d’avance!
Moi, je suis une quiche en informatique! J’ai essayé de lire attentivement votre article docteur, mais mon cerveau n’arrive même pas à concevoir « l’algorythmique »!…
J’ai Shazam sur mon Iphone, c’est purement et simplement divin, je ne peux pas m’en passer, et pourtant… J’ai une question très terre à terre: pourquoi n’ai-je droit qu’à 5 tags par mois (c’est une plaisanterie, j’en fais 5 par heure!) alors que ma fille, qui l’a téléchargé comme moi, en application gratuite, a Shazam en illimité?!!
Merci de me répondre, vous me rendrez le sourire!
Alors à mon tour d’être une quiche. ta question concerne un domaine que mon cerveau arrive très difficilement à cerner : le marketyng* 😉
Je n’ai aucune explication rationnelle, mais je dirais que si tu utilises autant Shazam, chère Galinette, tu pourrais te fendre de quelques dollars pour contribuer à financer une merveille de la technologie…
*si tu mets un « y » a algorithme, moi j’en met un aussi là, na!
Merci pour la réponse, c’est déjà ça! Vous comprenez que je suis très déçue… Alors si j’ai bien compris, je ne dois pas mettre des « y » là où il ne faut pas, par contre il faut que je mette la main à la poche si je veux taguer quand je veux! Merkiiii!
Blague à part, c’est en effet une histoire de sous, j’ai lu sur un forum que cette application était gratuite jusqu’à juillet 2010 (avec tags illimités,je m’entends). Bouhhhh!…
Moi, je suis une quiche en informatique! J’ai essayé de lire attentivement votre article docteur, mais mon cerveau n’arrive même pas à concevoir « l’algorythmique »!…
J’ai Shazam sur mon Iphone, c’est purement et simplement divin, je ne peux pas m’en passer, et pourtant… J’ai une question très terre à terre: pourquoi n’ai-je droit qu’à 5 tags par mois (c’est une plaisanterie, j’en fais 5 par heure!) alors que ma fille, qui l’a téléchargé comme moi, en application gratuite, a Shazam en illimité?!!
Merci de me répondre, vous me rendrez le sourire!
En passant, trouvé cet article en anglais qui explique aussi la méthode Shazam, avec un peu plus de graphiques
En passant, trouvé cet article en anglais qui explique aussi la méthode Shazam, avec un peu plus de graphiques
Bonjour je voudrais savoir s’il existe un éditeur de tags basé sur le même principe?
je m’explique,
afin de trier une bibliothèque de musique simplement on chargerai tous nos petits fichiers mp3 qui n’ont aucun tags ils serait ensuite comparés a la base de données de Shazam pour ensuite leur affecter les tags correspondant!
Ce serait vraiment génial
Bonjour je voudrais savoir s’il existe un éditeur de tags basé sur le même principe?
je m’explique,
afin de trier une bibliothèque de musique simplement on chargerai tous nos petits fichiers mp3 qui n’ont aucun tags ils serait ensuite comparés a la base de données de Shazam pour ensuite leur affecter les tags correspondant!
Ce serait vraiment génial
Bravo, bravo pour cet article. Je suis heureux d’apprendre le fond de la méthode Shazam, à savoir le spectrogramme + l’étude statistique qu’ils ont faite pour finalement se rendre compte qu’ils avaient peu de chances de se tromper.
Mais je suis certain qu’autour de ce noyau doit graviter un bon paquet de petits gadgets de traitement du signal, comme du filtrage de bruit, de l’autocorrélation, que sais-je encore ?
J’espère trouver d’autres informations,
encore bravo pour cet article très bien foutu et qui, en plus, m’a fait découvrir la merveilleuse voix de Florence Foster-Jenkins et m’a bien fait marrer pendant dix minutes.
à bientôt !
L.
Bravo, bravo pour cet article. Je suis heureux d’apprendre le fond de la méthode Shazam, à savoir le spectrogramme l’étude statistique qu’ils ont faite pour finalement se rendre compte qu’ils avaient peu de chances de se tromper.
Mais je suis certain qu’autour de ce noyau doit graviter un bon paquet de petits gadgets de traitement du signal, comme du filtrage de bruit, de l’autocorrélation, que sais-je encore ?
J’espère trouver d’autres informations,
encore bravo pour cet article très bien foutu et qui, en plus, m’a fait découvrir la merveilleuse voix de Florence Foster-Jenkins et m’a bien fait marrer pendant dix minutes.
à bientôt !
L.
Trouvé ça ici : http://www.commitstrip.com/fr/2012/10/16/histoire-vraie-comment-ma-mere-pense-que-shazam-fonctionne/
Trouvé ça ici : http://www.commitstrip.com/fr/2012/10/16/histoire-vraie-comment-ma-mere-pense-que-shazam-fonctionne/
Très sympa shazam, j’apprécie
. . . Mais en musique baroque il a des choses à apprendre (même quand le cd est publié chez harmonie muni ou glossa)
Très sympa shazam, j’apprécie
. . . Mais en musique baroque il a des choses à apprendre (même quand le cd est publié chez harmonie muni ou glossa)
bonjour,
Très intéressante explication.
je me demande comment schazam recueille tous ces morceaux de musique, comment elle alimente sa banque de données.
JeanGuillaume
Comme Shazam permet d’acheter la musique trouvée sur iTunes et qu’ils indiquent « Track samples provided courtesy of iTunes » en se balladant sur leur site, j’imagine qu’ils ont un accord avec Pomme…. D’autre part leurs résultats de l’an passé indiquent que leur revenu est versé presque intégralement à une entreprise » Broadcast Monitoring Inc » à laquelle ils ont vendu leur technologie en 2005. Et sur LinkedIn on découvre que Landmark Digital, citée dans l’article, appartient aussi à BMI…
Il est donc possible que les inventeurs aient fondé leur propre boite (BMI) qui vend la technologie de reconnaissance à Shazam et détient peut-être aussi la base de données…
bonjour,
Très intéressante explication.
je me demande comment schazam recueille tous ces morceaux de musique, comment elle alimente sa banque de données.
JeanGuillaume
Bonjour Tristan,
Shazam et votre application ainsi que de nombreuses autres sont de la famille des « recherche des plus proches voisins » ( https://fr.wikipedia.org/wiki/Recherche_des_plus_proches_voisins ) Concrètement vous devez caractériser vos fichiers, automatiquement ou manuellement par un certain nombre de valeurs/mots, et ensuite votre algo doit retrouver le document qui correspond le mieux aux critères de recherche.
En pratique, lorsque le nombre de documents et le nombre de dimensions (=nombre de valeurs/mots) augmente, on ne peut plus se permettre de parcourir tous les documents un à un et il faut trouver une « fonction de hachage » qui permet de retrouver un document presque instantanément. Le gros problème est que cette fonction doit être « locality sensitive » ( https://fr.wikipedia.org/wiki/Locality_sensitive_hashing ) : la fonction de hachage doit retourner la même valeur « banane » que vous cherchiez « texte correction algèbre » ou « solution de l’exercice sur les dérivées » qu’il contient …
Shazam résout ce problème en utilisant une fonction de hachage (secrète) qui produit beaucoup de collisions et en « croisant » les résultats correspondants. .
Une idée serait de vous inspirer de la solution « à la Google » qui repose sur https://fr.wikipedia.org/wiki/BigTable : faire une base de données indexée par les mots du contenu (ou de la description) de tous les fichiers, les enregistrements pointant sur les documents qui les contiennent. Ensuite faire une recherche des documents qui contiennent les N mots recherchés, les N combinaisons de N-1 mots recherchés si on ne trouve pas de correspondance parfaite etc.
Le problème auquel vous vous attaquez n’est donc pas facile du tout, documentez vous bien sur les solutions existantes avant de réinventer la roue. Bonne chance !
Bonjour,
Merci beaucoup pour votre réponse rapide et claire. On a essayé d’approfondir la recherche à partir des pistes que vous nous avez données, même si comme vous l’avez dit c’était costaud !
On a étudié tout l’aspect mathématique des fonctions de hachage avec notre prof de maths. On a toutefois du mal à mettre en relation ce qu’on a compris avec notre problème de départ.
Pourrais-je avoir votre adresse mail pour vous poser plus facilement des questions supplémentaires ?
Merci d’avance.
J’ai essayé d’envoyer le texte ci-dessous à l’adresse e-mail que vous avez indiquée, mais elle est bidon 😉 Quant à moi, je préfère la discussion ici car plus de monde en profite. Donc voilà :
Notez que je ne suis pas un véritables spécialiste de ce domaine. Actuellement je travaille plutôt sur des algorithmes d’optimisation et de géométrie.
Dans ce contexte, une alternative au hachage serait de caractériser chaque document par un point dans un espace à N dimensions pour pouvoir utiliser des structures comme https://en.wikipedia.org/wiki/R-tree pour la recherche du plus proche voisin. http://libspatialindex.github.io/ fait ça très bien, je l’utilise en python via http://libspatialindex.github.io/
Mais il faut tout de même trouver un moyen de réduire un document à un point de manière à ce qu’une recherche donne un point proche …
En faisant une rapide recherche bibliographique je suis tombé sur http://www.academia.edu/7710446/EFFICIENTLY_SEARCHING_NEAREST_NEIGHBOR_IN_DOCUMENTS_USING_KEYWORDS qui est inintéressant, mais contient une bibliographie d’articles utilisant différentes méthodes, ou des combinaisons de plusieurs méthodes.
Bonjour Tristan,
Shazam et votre application ainsi que de nombreuses autres sont de la famille des « recherche des plus proches voisins » ( https://fr.wikipedia.org/wiki/Recherche_des_plus_proches_voisins ) Concrètement vous devez caractériser vos fichiers, automatiquement ou manuellement par un certain nombre de valeurs/mots, et ensuite votre algo doit retrouver le document qui correspond le mieux aux critères de recherche.
En pratique, lorsque le nombre de documents et le nombre de dimensions (=nombre de valeurs/mots) augmente, on ne peut plus se permettre de parcourir tous les documents un à un et il faut trouver une « fonction de hachage » qui permet de retrouver un document presque instantanément. Le gros problème est que cette fonction doit être « locality sensitive » ( https://fr.wikipedia.org/wiki/Locality_sensitive_hashing ) : la fonction de hachage doit retourner la même valeur « banane » que vous cherchiez « texte correction algèbre » ou « solution de l’exercice sur les dérivées » qu’il contient …
Shazam résout ce problème en utilisant une fonction de hachage (secrète) qui produit beaucoup de collisions et en « croisant » les résultats correspondants. .
Une idée serait de vous inspirer de la solution « à la Google » qui repose sur https://fr.wikipedia.org/wiki/BigTable : faire une base de données indexée par les mots du contenu (ou de la description) de tous les fichiers, les enregistrements pointant sur les documents qui les contiennent. Ensuite faire une recherche des documents qui contiennent les N mots recherchés, les N combinaisons de N-1 mots recherchés si on ne trouve pas de correspondance parfaite etc.
Le problème auquel vous vous attaquez n’est donc pas facile du tout, documentez vous bien sur les solutions existantes avant de réinventer la roue. Bonne chance !
Salut
Juste pour dire (même avec beaucoup de retard) que ce billet, au delà d’éclairer ma lanterne m’a trop fait rire. Surtout le passage sur MIDOMI
Salut
Juste pour dire (même avec beaucoup de retard) que ce billet, au delà d’éclairer ma lanterne m’a trop fait rire. Surtout le passage sur MIDOMI
Pour moi, musixmatch c’est encore mieux que shazam ! C’est le même principe que shazam pour la détection de la musique mais ça te propose les paroles des chansons en temps réel (comme un karaoké !). À tester !
D’après http://evolver.fm/2013/04/12/best-app-for-identifying-music-shazam-soundhound-or-musixmatch/ « Shazam and Soundhound blew musiXmatch out of the water, correctly identifying nearly twice as many songs. Admittedly MusiXmatch is primarily a lyrics app with a music ID feature built-in, so this isn’t too surprising. »…
Donc l’algo de reconnaissance de Musixmatch n’a pas l’air à la hauteur, mais si le client (toi) préfère les fonctionnalités de paroles à la qualité de reconnaissance, alors c’est une bonne app.
Pour moi, musixmatch c’est encore mieux que shazam ! C’est le même principe que shazam pour la détection de la musique mais ça te propose les paroles des chansons en temps réel (comme un karaoké !). À tester !
trouvé http://www.soyoucode.com/2011/how-does-shazam-recognize-song qui est plus basé sur l’article [2] que sur le brevet [1]. A mon avis, le brevet est plus « génial » sur la méthode utilisée pour retrouver le morceau (par les 2 empreintes utilisées comme clefs) plutôt que l’article dont la méthode par corrélation est certainement efficace, mais lente.
trouvé http://www.soyoucode.com/2011/how-does-shazam-recognize-song qui est plus basé sur l’article [2] que sur le brevet [1]. A mon avis, le brevet est plus « génial » sur la méthode utilisée pour retrouver le morceau (par les 2 empreintes utilisées comme clefs) plutôt que l’article dont la méthode par corrélation est certainement efficace, mais lente.
Bonsoir Dr,
Je m’intéresse également à la techno de Shazam pour l’appliquer à des fins de reconnaissance de vidéo (passke finalement le vidéo et audio fingerprinting se traitent presque de la même manière).
Alors d’abord merci pour l’article et les sources associées, j’avais d’abord lu l’article mais le brevet est tout aussi intéressant !!
Par contre j’avoue ne pas trouver mention de la fonction de hachage que vous mentionnez… Pour moi, il s’agit d’une méthode accumulative, puisqu’elle s’appuie sur un histogramme calculé sur des matchings, eux mêmes calculés par la combinaison de paires de maxima locaux du spectrogramme. Les droites détectées dans une map t_database / t_sample s’accumulent et forment un pic dans un histogramme, ce qui permet de retrouver un (ou plusieurs) morceau(x) présentant des pics significatifs.
J’ai beau relire les papiers et je ne trouve pas de notion de base de données dont les clés seraient les fingerprints (les paires de max) ce qui est une vache de bonne idée d’ailleurs…j’ai du coup du mal à faire le lien avec les calculs que vous développez. Pourriez vous m’éclairer ?
Merci d’avance
Bonsoir Dr,
Je m’intéresse également à la techno de Shazam pour l’appliquer à des fins de reconnaissance de vidéo (passke finalement le vidéo et audio fingerprinting se traitent presque de la même manière).
Alors d’abord merci pour l’article et les sources associées, j’avais d’abord lu l’article mais le brevet est tout aussi intéressant !!
Par contre j’avoue ne pas trouver mention de la fonction de hachage que vous mentionnez… Pour moi, il s’agit d’une méthode accumulative, puisqu’elle s’appuie sur un histogramme calculé sur des matchings, eux mêmes calculés par la combinaison de paires de maxima locaux du spectrogramme. Les droites détectées dans une map t_database / t_sample s’accumulent et forment un pic dans un histogramme, ce qui permet de retrouver un (ou plusieurs) morceau(x) présentant des pics significatifs.
J’ai beau relire les papiers et je ne trouve pas de notion de base de données dont les clés seraient les fingerprints (les paires de max) ce qui est une vache de bonne idée d’ailleurs…j’ai du coup du mal à faire le lien avec les calculs que vous développez. Pourriez vous m’éclairer ?
Merci d’avance
Ah ben voilà en classant les coms je lis votre dernier commentaire.. Je me replonge dans le brevet afin d’essayer de débusquer cette fameuse fonction de hashage… So far j’ai tout de même l’impression qu’il s’agit des paires deux locaux… Désolé pour le dérangement 😉
Pas de problème 😉
Parmi mes nombreux brouillons d’articles à finir un de ces jours il y en a un sur la recherche d’images dupliquées. J’ai fait un petit programme en Python qui utilise le hash d’images décrit ici http://www.hackerfactor.com/blog/index.php?/archives/432-Looks-Like-It.html et j’ai été très étonné de voir comme il fonctionne bien en 8x8x1bit seulement. Le code est en bas de https://github.com/goulu/Goulib/blob/master/Goulib/image.py si ça peut vous être utile.
Yes merci Doc ! j’y jetterai sans doute un coup d’oeil 🙂
Moi au cas où ca vous intéresserait j’ai fini un proto sous matlab. il code le papier, mais clairement, ca tient pas le temps reel :). Alors deja, la reponse est dans la question, c’est en Matlab (meme avec mon i7 tout neuf, clairement, ca le fait pas, mais c’est tout de meme bien pratique). Autant pour la computation des signatures, c’est plutot pas mal puisque un audio de 30s est encodé en 10s~15s (en fonction du recouvrement des sous-fenetres et du nombre de points de la fft), autant pour la recherche et la fabrication de l’histogramme, on en est loin, d’ou mon intérêt pour cette fameuse fonction de hashage.
Par contre, d’apres mes premiers tests, ca marche plutot pas mal…on peut facilement retrouver un morceau tant le pic de l’histo est important (et discriminant par rapport à un non match), trouver l’offset quand le sample est incomplet tout ca…ca fitte plutot bien mes besoins !
Merci en tout cas pour cet article, je sens que je vais parcourir un peu le site, ca m’a l’air être truffé de choses sympathiques
Laurent
Ah ben voilà en classant les coms je lis votre dernier commentaire.. Je me replonge dans le brevet afin d’essayer de débusquer cette fameuse fonction de hashage… So far j’ai tout de même l’impression qu’il s’agit des paires deux locaux… Désolé pour le dérangement 😉
Bonsoir,
Je suis élève en cinquième secondaire (Belgique) et en option math forte.
J’ai trouvé votre article très intéressant et j’ai donc décidé d’en faire le sujet de ma présentation de fin d’année.
Cependant, j’ai vérifié sur d’autres sites et j’ai trouvé le calcul des empreintes (http://www.lesnumeriques.com/audio/magie-shazam-dans-entrailles-algorithme-a2375.html ) or vous nous dites que le brevet est très vague là-dessus alors que cet article est lui aussi fondé sur le brevet d’Avery Lee-Chun Wang.
Je me demande donc quelle source croire (j’ai vérifié d’autres articles mais aucun n’étaient aussi complets que le votre et le lien que je vous ai envoyé).
D’autres différences sont par exemple le nombre de morceaux, votre article en donne 11 millions et l’autre 8 millions …
La meilleure façon de vérifier est de regarder le brevet même (qui requiert une maîtrise du vocabulaire informatique et qui est en anglais). Je l’ai parcouru mais je n’ai pas trouvé l’endroit qui spécifie le nombre de morceaux ni comment vous avez su que la mémoire totale de la base de données est de 54 Gigabyte. Après, je ne l’ai sûrement pas lu en profondeur donc ça peut-être normal, mais j’aimerais quand même être sûre des sources sur lesquelles se base mon travail.
De plus, le calcul expliqué par l’autre article correspond à celui du brevet…
Je vous écris donc pour vous demander si ça vous dérangerait de m’expliquer comment vous avez trouvé et, si possible, me dire à quelle page du brevet cela stipule ?
Merci d’avance et merci pour cet article extrêmement enrichissant !
De plus, je ne comprends pas pourquoi vous dites qu’une empreinte est stockée en 32 bits mais que 32 bits peuvent coder 4 milliards de données … ?
Bonjour Duong,
l’article des numériques n’existait pas encore en 2009 quand j’ai écrit le mien, que j’avais basé uniquement sur ce que j’avais compris du brevet et de l’article http://www.ee.columbia.edu/~dpwe/papers/Wang03-shazam.pdf (référence [2]), et peut être un peu trop résumé, je l’admets. L’article des numériques est très détaillé sur le calcul des empreintes, le rejet du bruit etc, mais pas trop sur la structure utilisée pour la recherche rapide des empreintes dans une grosse base de données.
La structure utilisée initialement est décrite aux paragraphes 2.2 et 2.3 de [2]: les « hash » de 32 bits sont liés à 32 bits d’information (ID du morceau + décalage temporel depuis l’empreinte précédente. Pour l’ID du morceau il faut log2(N morceaux) donc avec 24 bits on peut identifier 2^24 = 16.7 morceaux, assez pour les 8 millions de morceaux que connaissait Shazam en 2009 et encore assez aujourd’hui pour 11 millions.
Dans [2] paragraphe 2.3, Wang suggère de mettre toutes les empreintes+données (=64 bits) dans une liste triée selon les empreintes et de faire une recherche O(N.logN) dedans. Mais ailleurs je ne sais plus où il propose d’utiliser directement le « hash » comme adresse dans une mémoire de 2^32 = 4’294’967’296 enregistrements contenant chacun les 32 bits de données du « hash-adresse » correspondant. Ainsi la recherche des morceaux correspondant à un hash est instantanée (O(1)), ce que je trouve génial.
Mais 11 millions de morceaux x ~3 minutes x ~10 hashes par seconde font 19.8 milliards de hashes, ce qui occupe en principe 80 Gb (32 bits par hash). C’est presque 5 fois plus que 2^32 : ça signifie que chaque hash peut désormais correspondre à 5 morceaux en moyenne. Il faut donc utiliser une technique de « résolution des collisions » qui va consommer un peu plus de mémoire, en effet. Mais pas tant que ça.
Comme vous le voyez, et je pense que c’est un point intéressant à soulever dans votre travail, un brevet bien fait décrit souvent une invention en terme assez généraux (et souvent très compliqués) pour la protéger, mais sans les détails qui permettraient effectivement de la copier. Il faut souvent beaucoup de travail de « reverse engineering », et parfois lire entre les lignes pour éviter des pièges que l’inventeur met parfois délibérément dans son brevet pour orienter des copieurs sur de fausses pistes. Je ne dis pas que c’est le cas pour Shazam, mais vous voyez qu’ils ne disent pas tout, et que certaines choses qu’ils disent semblent exagérément compliquées…
Donc pour résumer je dirais que l’article des numériques est plus récent et mieux que le mien sur le calcul des empreintes, mais que le mien décrit mieux ce qui est fait – ou pourrait être fait – ou ce que j’aurais fait – pour retrouver le plus vite possible les morceaux correspondant aux empreintes . Je vous laisse faire le tri 😉
Bonjour Dr,
Merci pour votre réponse très complète et rapide ! Ça m’a beaucoup éclairée et je me baserai sur votre article pour ma présentation (en n’oubliant pas de mentionner votre blog).
Merci encore pour toutes ces informations passionnantes!
Bonsoir,
Je suis élève en cinquième secondaire (Belgique) et en option math forte.
J’ai trouvé votre article très intéressant et j’ai donc décidé d’en faire le sujet de ma présentation de fin d’année.
Cependant, j’ai vérifié sur d’autres sites et j’ai trouvé le calcul des empreintes (http://www.lesnumeriques.com/audio/magie-shazam-dans-entrailles-algorithme-a2375.html ) or vous nous dites que le brevet est très vague là-dessus alors que cet article est lui aussi fondé sur le brevet d’Avery Lee-Chun Wang.
Je me demande donc quelle source croire (j’ai vérifié d’autres articles mais aucun n’étaient aussi complets que le votre et le lien que je vous ai envoyé).
D’autres différences sont par exemple le nombre de morceaux, votre article en donne 11 millions et l’autre 8 millions …
La meilleure façon de vérifier est de regarder le brevet même (qui requiert une maîtrise du vocabulaire informatique et qui est en anglais). Je l’ai parcouru mais je n’ai pas trouvé l’endroit qui spécifie le nombre de morceaux ni comment vous avez su que la mémoire totale de la base de données est de 54 Gigabyte. Après, je ne l’ai sûrement pas lu en profondeur donc ça peut-être normal, mais j’aimerais quand même être sûre des sources sur lesquelles se base mon travail.
De plus, le calcul expliqué par l’autre article correspond à celui du brevet…
Je vous écris donc pour vous demander si ça vous dérangerait de m’expliquer comment vous avez trouvé et, si possible, me dire à quelle page du brevet cela stipule ?
Merci d’avance et merci pour cet article extrêmement enrichissant !
Que faire, sur mon iPhone 6, quand Shazam devient sourd et n’entend pas les morceaux et demande de se rapprocher de la source. D’habitude ça marche même à 2 ou 3 mètres, mais là même carrément à quelques centimètres il n’entend rien.
Que faire, sur mon iPhone 6, quand Shazam devient sourd et n’entend pas les morceaux et demande de se rapprocher de la source. D’habitude ça marche même à 2 ou 3 mètres, mais là même carrément à quelques centimètres il n’entend rien.
Bonjour DrGoulu,
J’espere que ce petit message vous trouve en grande forme, quelque part sur le globe…
Le brevet de WANG et CULBERT datant de 2003, y a-t-il des chances que l’algorithme de shazaam se retrouve dans d’autres applications concurrentes, même s’il est un peu ‘fade’ techniquement?
En regardant le brevet susmentionné, il n’y a effectivement pas beaucoup d’informations fondamentalement nouvelles. La procedure de recherche correspond à celle d’une attaque de decryptage de texte basique, basée sur les empreintes d’occurences alphabetiques des langues.
Est-ce que vous en savez plus sur la codification de l’empreinte elle-même?
Salutation depuis les environs de Grenchen
Salut Pascal,
non je n’ai pas cherché plus loin …